
看得我嫑嫑的,避免搜尋引擎走光你的隱私





SEO優化會希望搜尋引擎找到我們想要曝光的內容,盡量出現在越前面的搜尋結果頁(SERP)。 不過,很多時候,某些網站或是某些內容,我們並不希望被人知道,這個時候我們就要善用robots.txt來為我們的隱私權做宣告。
robots.txt的撰寫
內容主要會以「User-agent」、「Disallow 」和「Allow」構成。
User-agent主要是針對使用者瀏覽器和搜尋引擎機器人(俗成爬蟲)來做宣告,可以特別指定想要給哪一個搜尋引擎觀看內容,不過,絕大多數的情形下會採用預設的 User-agent : *
User-agent : * 表示全體接受
Disallow 告訴爬蟲不要花費時間在我們所指定的目錄或路徑
Allow 則表示歡迎爬蟲去探索
若是經營大型網站或是電商平台,可能就會針對網站不同的部位來設定,希望廣告的爬蟲、圖片的爬蟲快速爬取,找到我們網站上的廣告或圖片資源對應的位置,讓爬蟲不需要從頭到尾找過我們的網站。
假設我們經營的是有會員的社群網站,我們會希望如果有包含會員隱私的內容,不要成為搜尋時,曝光到搜尋結果頁上,意外走光會員的隱私。我們就可以指定搜尋引擎不要去探索有關會員(member)的相關隱私資料。
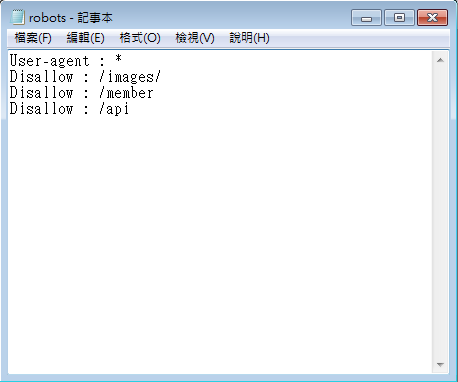
上述的例子,就是告訴爬蟲我們的images目錄底下的所有資源 和 /member 路徑之後的都不希望被搜尋引擎檢索,然後供人搜尋時被找到。
在寫好robots.txt記得要上傳到網站的根目錄,或是與網站的首頁同一層級的目錄位置,建議網站在正式對外公開時,就要把robots.txt和sitemap.xml一起上傳,可以讓搜尋引擎提早完成登錄那些不希望被搜尋引擎登錄的頁面。robots.txt內容不宜時常變動,若有需要修改robots.txt的內容,建議可以使用google search console,裡面所提供的robots.txt 測試工具,可以修改後做測試,沒問題後選擇提交,就可以更新robots.txt
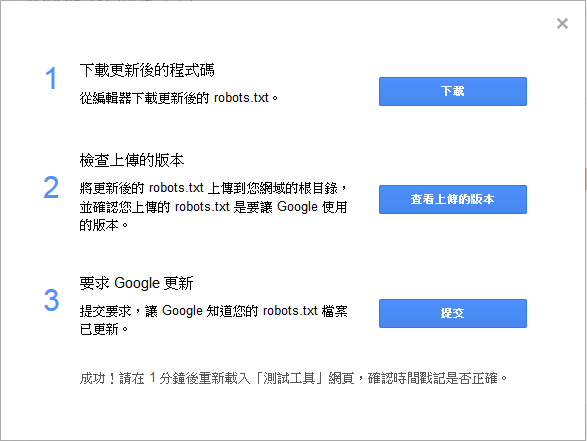
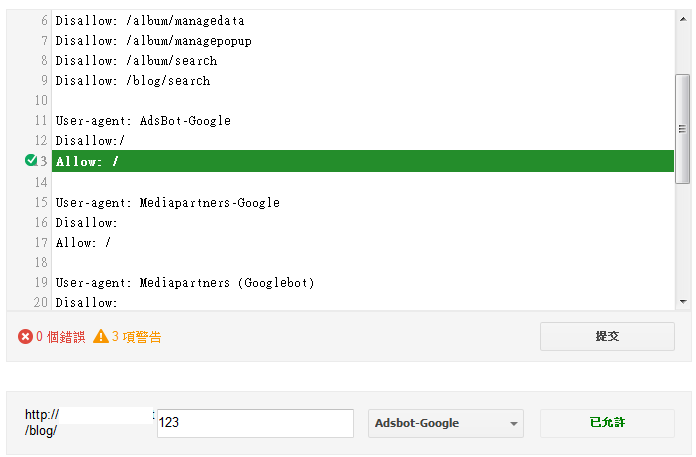
如果不放心也可以在已經設定好要封鎖的網址,在下方的輸入框輸入後做測試
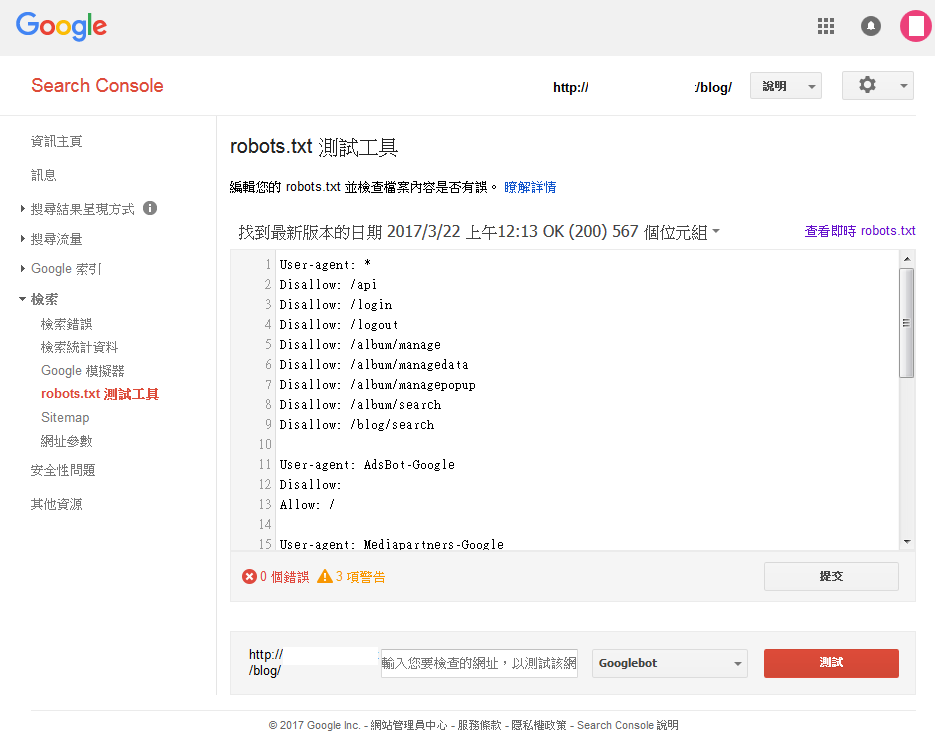
像是以Adsbot-Google這個爬蟲為例,我們告訴他不要來爬我的網站,設定好Disallow: / ,就可以測試,並且得到已封鎖
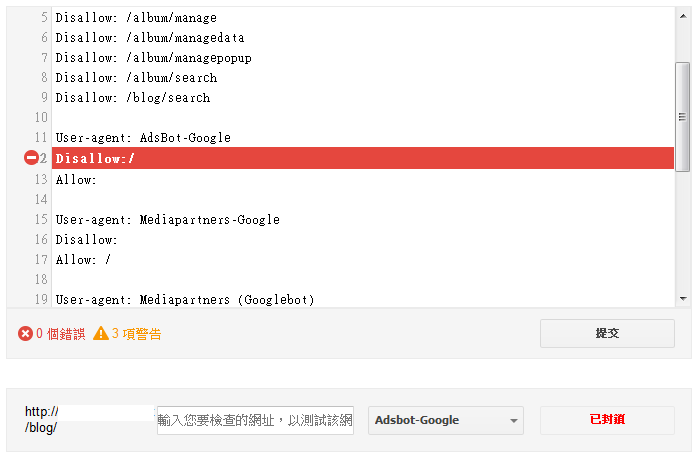
但是,如果不幸很迷糊的Disallow和Allow都設定成同樣的狀況,那麼google這邊還是會認為是被Allow去探索的,因為每一個爬蟲的設定都會依照不同的開發者而有不同的定義,雖然google可以判斷兩邊都設定的矛盾情況,而採取Allow,但不代表其他的爬蟲會有同樣結果。
一般簡單的作法,我們只會設定我們不想要被探索的資源,Allow不去填寫,也就是默認可以被探索。
其他防止網頁被存取的方法
1. 在網頁的之間使用「noindex」
就等於宣示爬蟲這個網頁不需要被探索,讓爬蟲花時間去探索其他的網頁。
不過,前提是這個網頁是沒有被robots.txt所封鎖的,如果robots.txt已經被封鎖那麼爬蟲自然就不會去追究其內容,所以即使下達noindex,爬蟲也不會知道。
<head>
...
<meta name="robots" content="noindex">
...
</head>
2. 使用.htaccess
這個方法是進階的設定方式,建議有實際管理網站主機的讀者來操作,或者你有一個可以不怕被玩壞的網站也很適合拿來練功
.htaccess Editor 是一個值得推薦的.htaccess線上工具,可以協助我們設定.htaccess檔案
可以透過.htaccess設定密碼來保護網站內容,也可以使用403禁止網頁被探索。
2017/04/11